Dubbo低版本消费者Client线程无限膨胀及解决
背景陈述
Dubbo在 < 2.7.5的版本中(我们使用的是2.6.7),每个端到端的连接(也叫Channel,以IP + 端口确定一条端到端连接),都会有自己私有的线程池,用来给消费侧应用的Dubbo调用的响应进行线程池提交处理(也就是底层通信组件(Netty)只负责把响应Message提交到线程池就结束了,防止Netty内部因为Dubbo业务不稳定而导致信息阻塞)。
但是每个Channel私有的线程池默认使用的是线程数量无上限(Integer.max)的线程数配置,再结合任务队列使用的SynchronousQueue,一旦线程池资源处理不过来,就会持续新建线程处理队列消息。
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS);
int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE);
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE);
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
# 代码详见: com.alibaba.dubbo.common.threadpool.support.cached.CachedThreadPool#getExecutor
既有的Dubbo调用图示如下所示,注意看,每个Channel(或者叫Client更严谨)都有自己私有的线程池,其中每个线程池的线程数量无上限;
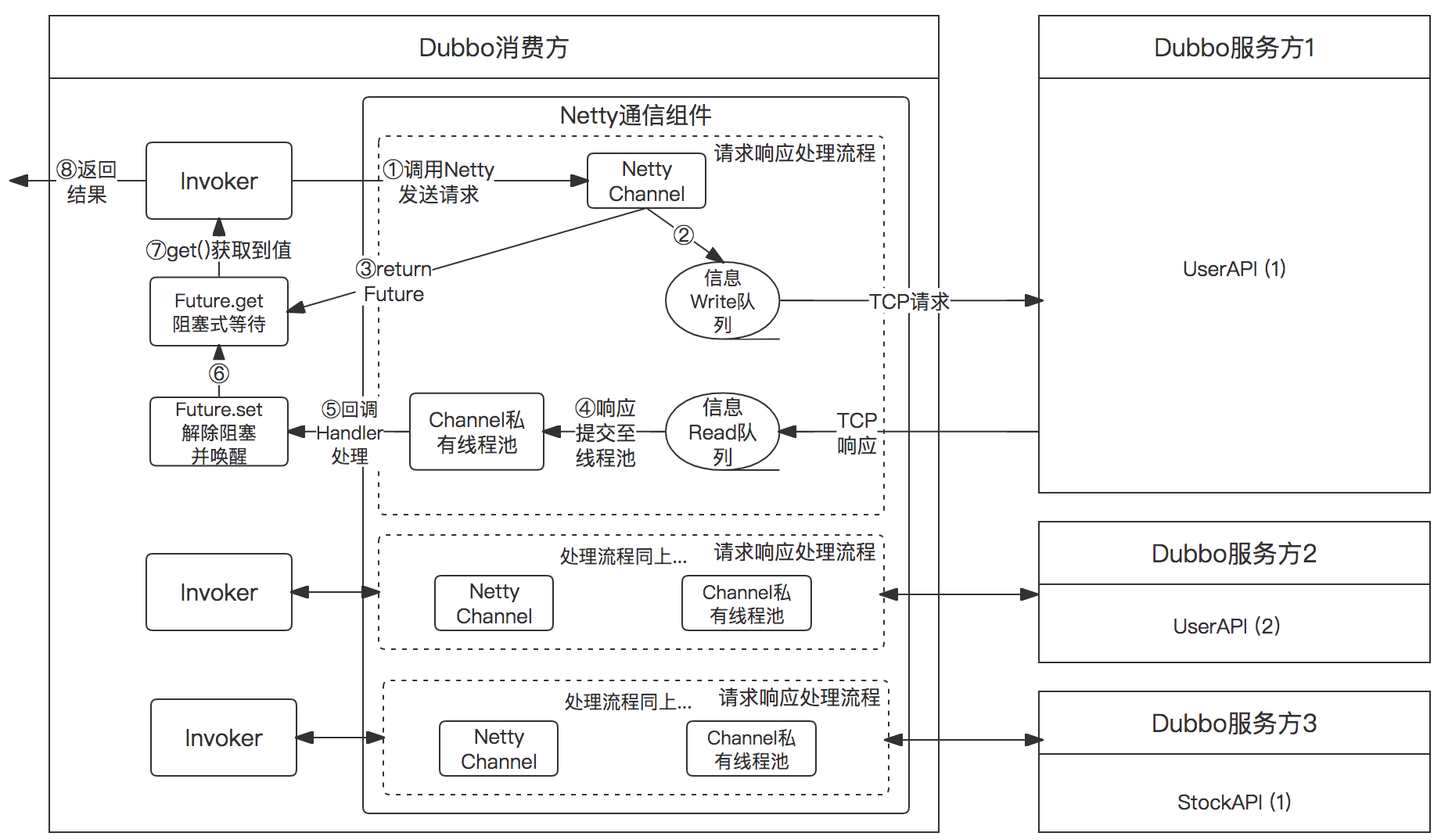
Dubbo的问题和瓶颈
这个方案造成的问题:新建线程越来越多之后,应用在线程调度、上下文切换上的系统开销可能已经远大于业务开销,造成业务得不到及时处理并导致RT增高。
这个现象在商详这种有大量Dubbo消费需求的应用中更为突显,我通过ab工具实测了下,发现正常情况下,商详应用的私有线程池数量总和大概是100多个左右,而在调用量很大的时候,这些私有线程池数量总和会急剧增加到1k+ ,而此时,商详整个的Web请求RT也在快速增长。作为对比,商详应用在日常流量下Java总线程数也才800个左右。
我们知道,Web应用优化初期想要提高QPS,最简单的办法就是提高并发数,也就是增加业务处理线程。但随着线程数的增多,系统对业务逻辑之外的线程调度、线程资源竞争、线程上下文切换等的开销也会慢慢增大,RT也可能会慢慢增长。系统在给定QPS和RT目标之后,通常会有一个最佳线程数,一旦超过这个线程数,RT会随着线程数急剧增长,QPS也会进入瓶颈甚至衰退期。因此应用一定要合理控制自己各业务的线程数。

Dubbo官方的解决思路
针对这个Dubbo的性能瓶颈问题,目前Dubbo的解决思路是(Dubbo 2.7.5及以后):伪造一个类似线程池机制的假线程池(ThreadlessExecutor),它的作用是暂时接收任务,但不处理,转而交由业务线程(也就是一直在Future.get()那里阻塞的线程)主动向该假线程池中索取属于自己的响应任务并执行。毕竟,与其让业务线程一直等待,还不如让他自主进行自己期待的响应消息的处理。对应代码
@Override
public Result get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (executor != null && executor instanceof ThreadlessExecutor) {
ThreadlessExecutor threadlessExecutor = (ThreadlessExecutor) executor;
// 主动索取属于自己的响应任务并自主处理
threadlessExecutor.waitAndDrain();
}
return responseFuture.get(timeout, unit);
}
注意上面的代码出现了if分支改造(老版本没有这段if代码),也就是Dubbo低版本没办法通过SPI扩展的方式使用上述解决方案,必须修改低版本的源代码来实现。
对应调用流程图解如下所示:第一个流程是常规流程;第二个流程是使用ThreadlessExecutor方案后的流程(为便于说明,可能部分内容有精简抽象)
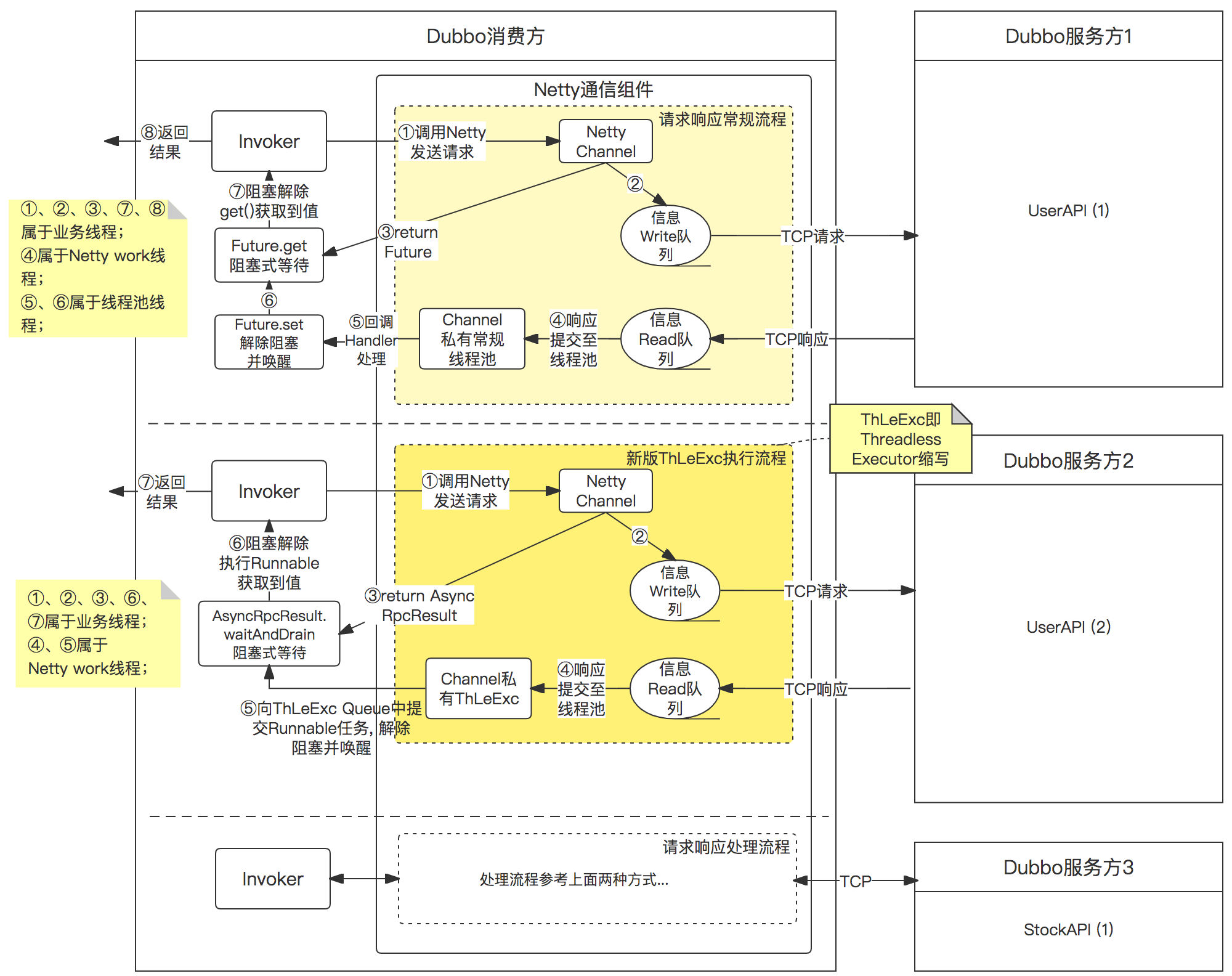
我们的解决思路
现在面临的问题是:有没有办法在不修改代码的前提下,仅通过SPI扩展的方式来解决上面提到的Dubbo瓶颈问题呢?我们自己的方案是:既然线程池是私有的,而且会无限创建,那么我们针对该问题优化下就好了:提供一个所有消费者共享的线程池,我们叫GSF线程池,而且限制总线程数量和任务队列长度。
那么问题又来了,万一瞬时响应消息太多,一个线程池处理不过来怎么办?复用Dubbo既有逻辑,1)如果GSF共享线程池处理不过来,则降级使用Channel的内部共享线程池处理,如果获取Channel的内部共享线程池失败,则降级使用当前线程(即Netty的worker线程)进行处理。这个降级策略是通过使用自建的RejectedExecutionHandler来实现的。
使用Gsf共享线程池的Dubbo调用图示:
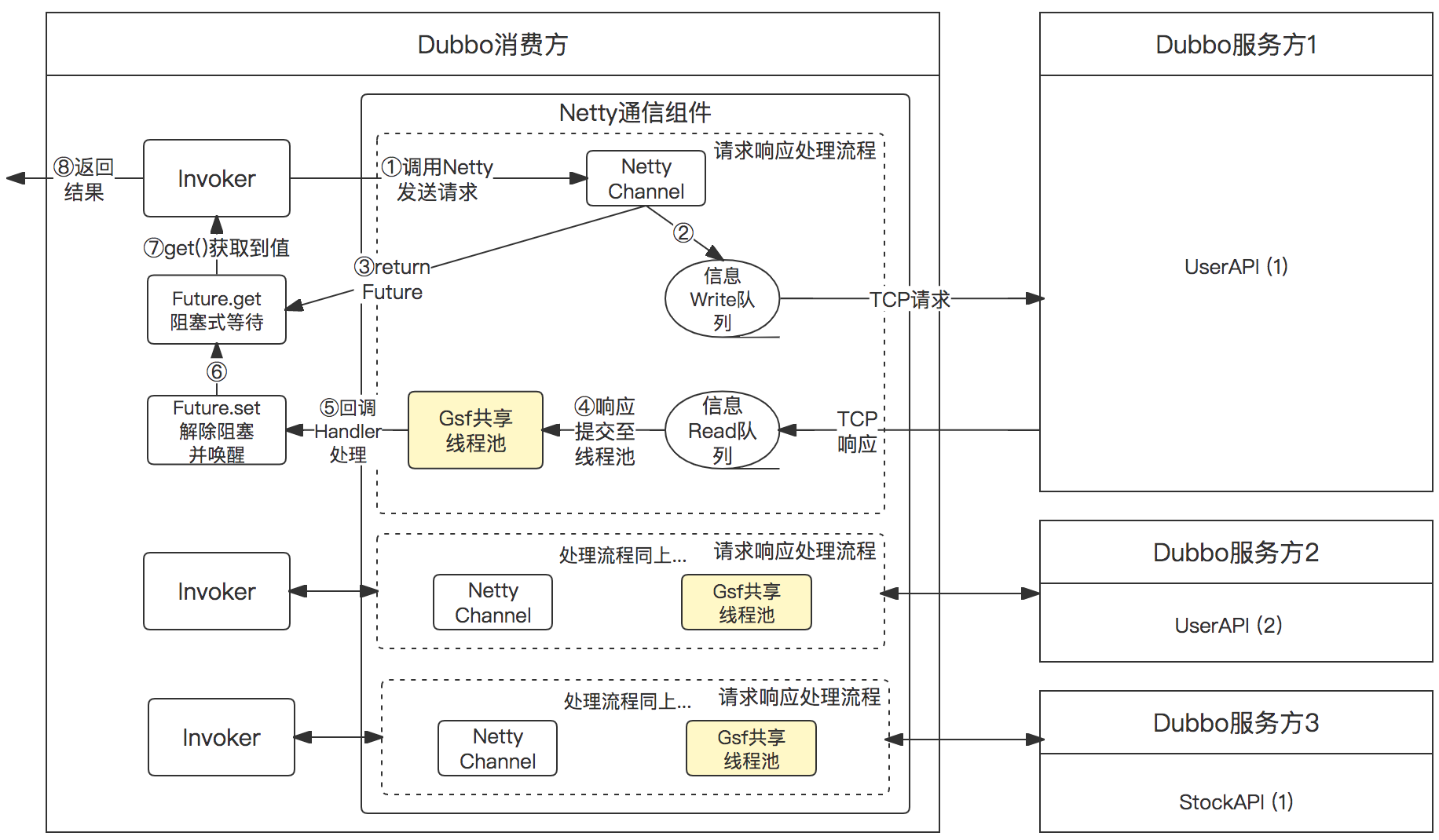
使用效果说明
之前商详在压测的时候,通过调用链平台可以看到有大量的Dubbo接口调用,其服务端耗时很低,但消费端的调用链路耗时却很长,通过上面的图示可以看到,造成这一现象的原因要么是write信息一直在等待被发送,要么是read信息一直等待被处理,导致Future.get()阻塞的时间较长。write信息的操作由于是Netty内部的事情不好介入和优化,所以我们尝试优化Dubbo中的回调线程池。
当时商详上线自建的GSF threadpool之后,通过调用链平台可以看到原先消费端调用链路耗时很长,但服务端耗时很低的现象已经几乎没再发生了,也就是说至少我们猜测的这里存在的瓶颈问题被解决和优化了。
自主实现的GSF threadpool代码也分享下,方便大家有需要了自取: https://gist.github.com/HelloLyfing/328217c39b51fb0fe43d6eb301d35312
参考
https://cloud.tencent.com/developer/article/1587137